
Why Spark?
Because Spark is a general-purpose framework for cluster computing, it is used for a diverse range of applications. Spark will add significant value to the increasingly hybridized world of big data tools and platforms. Spark and its component technologies—as a unified stack or as discrete components—will quickly find their spot of use cases, applications and deployment zones where they sparkle brightest.
Of course, these are imprecise disciplines and usage patterns, and many folks have skills from both, sometimes playing the role of the investigating data scientist, and then “changing hats” and writing a hardened data processing application. Nonetheless, it can be illuminating to consider the two groups and their respective use cases separately.
Spark is essentially an evolution of Hadoop, adding its own query dialect—Spark SQL—and associated query processing engine as a layer that Spark applications can use instead of NoSQL, HiveQL or other query tools. Or you can, if you wish, deploy Spark SQL in a fluid query environment that can abstract all of these query interfaces to access and manipulate any data that’s stored on the data warehouse, Hadoop clusters and other platforms within the LDW.
How to build Real Time application using Spark:
You can build real time application using Spark eco-system. Let’s I explain how the components work within the Spark ecosystem. Spark Streaming receives live input data streams and divides the data into batches, which are then processed by the Spark engine to generate the final stream of batched results.

In Spark Streaming, these batches of data are called DStreams (discretized streams), continuous streams of data represented as a sequence of RDDs, which are Spark’s core abstraction for its data processing model.
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from many sources like Kafka, Flume, Twitter, ZeroMQ, Kinesis, or TCP sockets, and can be processed using complex algorithms expressed with high-level functions like map, reduce, join and window. Finally, processed data can be pushed out to filesystems, databases, and live dashboards. In fact, you can apply Spark’s machine learning and graph processing algorithms on data streams.

Spark SQL is a Spark module for structured data processing. Unlike the basic Spark RDD API, the interfaces provided by Spark SQL provide Spark with more information about the structure of both the data and the computation being performed. Internally, Spark SQL uses this extra information to perform extra optimizations. There are several ways to interact with Spark SQL including SQL, the DataFrames API and the Datasets API. When computing a result the same execution engine is used, independent of which API/language you are using to express the computation. This unification means that developers can easily switch back and forth between the various APIs based on which provides the most natural way to express a given transformation.
Spark SQL, the SQL-like extension for the Spark API also has a programming abstraction called DataFrames, which are distributed collections of data organized into named columns. In this blog, you are making use of Spark’s ability to convert RDDs into DataFrames in order to present them as temporary tables that can be manipulated using SQL queries.
Use case of Real time application design Web Analytics application:
Let’s take a simple web analytics application as an example. Imagine that you are providing a simple service that collects, stores, and processes data about user access details for your client websites. Let’s say it only collects a user ID, web page URL, and timestamp. Although there are many ways of approaching it, we can uses Spark Streaming and Spark SQL to build a solution because we want our developers to be able to run SQL queries directly on the incoming data stream instead of compiling new Spark applications every time there is a new question to be asked.
Credit Card Fraud Detection:
The credit card fraud, and credit card companies want to know when and where it’s happening so they can stop it.
Banks and credit card companies are on the hook to resolve fraudulent charges at the earliest, so they want to detect/block as many of them as soon as possible. They already have sophisticated mathematical models to detect possible bogus transactions, but these models are applied in a batch environment at a later stage. How does one deploy them in real-time?
Apache Spark Streaming, makes it possible for banks to process transactions and detect fraud in real time against previously identified fraud footprints. Within Spark, in-coming transaction feeds are checked against a known database and if there is a match, a real-time trigger can be set up to the call centre personnel who can then validate the transaction instantly with the credit card owner. If not, the data is stored on Hadoop, where it can be used to continuously update the models in the background through deeper machine learning.
I am adding Benchmarks for SQL-on-Hadoop (on demand):
Redshift – a hosted MPP database offered by Amazon.com based on the ParAccel data warehouse. We tested Redshift on HDDs.Hive – a Hadoop-based data warehousing system. (v0.12)Shark (Spark SQL) – a Hive-compatible SQL engine which runs on top of the Spark computing framework. (v0.8.1)Impala – a Hive-compatible* SQL engine with its own MPP-like execution engine. (v1.2.3)Tez – Tez is a next generation Hadoop execution engine currently in development (v0.2.0)
Query to Scan the table:
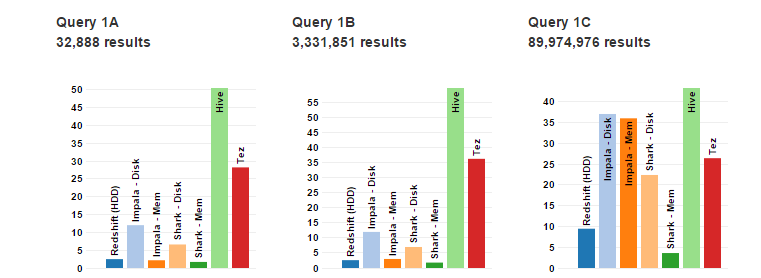
The best performers are Impala (mem) and Spark-SQL (mem) which see excellent throughput by avoiding disk. Both Shark/SparkSQL and Impala outperform Hive by 3-4X due in part to more efficient task launching and scheduling.
Query on complex Join on tables:
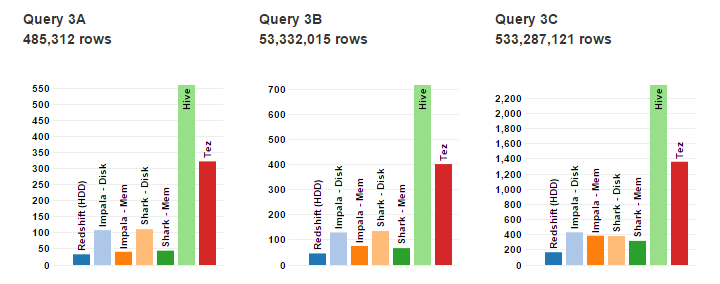
Article by channel:
Everything you need to know about Digital Transformation
The best articles, news and events direct to your inbox
Read more articles tagged: Featured