
“There falls the words of fools about my ears…Answers everywhere, promising solutions to my fears,leading through halls with no doors in the walls,and leave me in the darkness.”The Silence of a Candle (Ralph Towner)
Rest assured, this article will not be a sales pitch promising that Predictive Analytics is The Answer to everything. Instead, it will be a snapshot of a complex topic. But first, what is “Predictive Analytics”? Here are two brief examples:
- A model developed by a data scientist at a university used to identify students at high risk of defaulting on student loans.
- Models built by a data scientist at a financial services company designed to identify customers most likely to invest in certain new retirement funds.
I was the data scientist … and it was the 1980s. The terms “data scientist,” “big data” and “customer relationship management” (CRM) were not used and predictive analytics was called predictive modeling, the origins of which can be traced back centuries to epidemiology, actuarial science, astronomy and other fields. Banks had developed credit scoring systems based on statistical models at least as far back as the 1950s and the approach I used for my student loan model was adapted from established practice.
Myth-busting
Many misunderstandings surround predictive analytics. Though much of the buzz associates it with marketing, most predictive analytics has no connection with marketing at all. Medical and pharmaceutical research, fraud detection, HR, computer network security and (more notoriously) military and national security are just some of the other areas where predictive analytics is used. Marketing applications are most common in industries which have detailed consumer data, such as retailing, banking, insurance, travel, hospitality and telecommunications. A few examples of how it is used in marketing are CRM, retail recommender systems, direct marketing, targeted ads and analysis of Web site traffic.
There is no requirement that predictive analytics data must be big. Sometimes the data consist of just a few hundred observations, as in my student loan model and some survey-based segmentation typing tools. Massive, high-velocity, streaming data are also used but not required – they are the exception not the rule. This is also true of real-time analytics. Data can be either structured or unstructured.
Predictive analytics is best thought of as a process conducted by a team of people with diverse skills and requirements. Modeling is just one step and undertaken without clear business objectives or data that have not been cleaned will almost certainly lead to failure. The Cross Industry Standard Process for Data Mining (CRISP-DM) neatly summarizes this process:
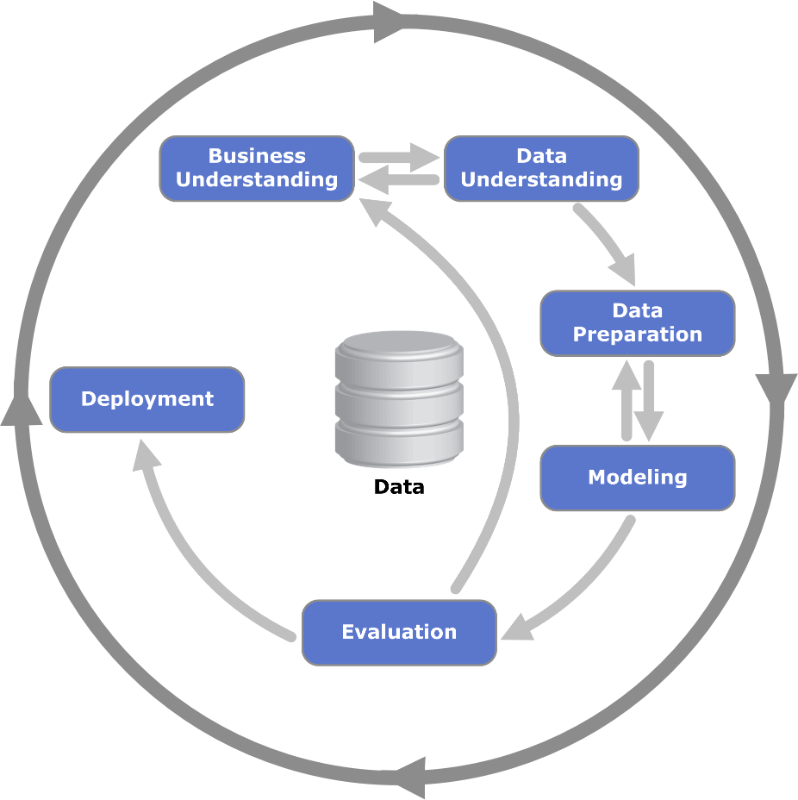
Although parts of this process can be automated, more data and algorithms have not rendered the human analyst obsolete. According to no lesser authorities than Leo Breiman and Adele Cutler, the developers of the popular random forests algorithm, “The cleverest algorithms are no substitute for human intelligence and knowledge of the data in the problem. Take the output of random forests not as absolute truth but as smart computer generated guesses that may be helpful in leading to a deeper understanding of the problem.”
Core concepts of predictive analytics
Now that I have hopefully cleared up some of the misunderstandings about predictive analytics, it’s time for a closer look at how it works. First, in predictive analytics existing data are used to develop a model that scores new data. By score, I mean any of the following:
- classifying into the most probable group (will purchase/will not purchase);
- assigning a probability score (probability of purchase); or
- predicting a quantity (how much will spend).
By new, I refer to data not used to build the model – data that do not yet exist (e.g., future customers) or data deliberately set aside when the model was built (a hold-out sample). By model, in this article I mean either of the following:
- an equation or system of equations used to represent the process that generated the data – a statistical model; or
- a computer algorithm designed for pattern recognition – a machine learner.
These are not official definitions, and terms such as “statistics” and “machine learning” are used ambiguously even by academics. In this article I also use “predictive analytics” where “data mining” or “Big Data” might be preferred by others. Like many people, I tend to use these terms interchangeably and sometimes a bit carelessly.
Contrary to what you may have heard, statistical and research fundamentals have become even more important with the availability of more data. Sampling – an essential part of most research (not just market surveys) – is one example of this. Predictive analytics models are typically developed on a sample of our data since we seldom need zillions of records to develop and evaluate a model. Complex sampling and weighting may be used when predicting rare events such as fraud. Knowledge of experimental and quasi-experimental designs is also essential – for instance when running different campaigns among different customer groups – as is a sound grasp of causal inference (e.g., “Why isn’t our campaign working?”).
There are many not-so-glamorous sides to predictive analytics and it nearly always involves a considerable amount of janitorial work. Many data fields are exhaust – for example, by-products of transactional or operational processes – and not useful in predictive analytics. Most data actually have little or no marketing value, so bigger is not necessarily better! Moreover, big comes in many sizes and big data is often small data repeated many times and can be substantially reduced at the pre-processing stage. For example, a project may need data on consumer purchases of a single food category over a twelve-month period, not every single transaction each customer has made in the past five years.
Even supposedly clean data can turn out to be very messy and data scientists usually allocate a substantial amount of time to data cleaning and setup. By contrast, they typically spend only 10 to 20 percent of their time on model building and evaluation and, since predictive analytics is normally a team effort, these parts of the process consume just a fraction of total person-hours.
Model building
Any sample has its idiosyncrasies. To develop a predictive model that generalizes well to new data we must try to avoid modelling noise in our data, which is known as overfitting. Overfitting causes model accuracy to decline when applied to new data. To reduce this risk we use a training sample to develop our model and a validation sample to estimate the accuracy of our candidate models on new data. Statistical methods normally have many options and machine learners many tuning parameters, and we need a good idea of which method, options and parameter-settings will work best. Overfitting is especially troublesome when there are few cases and many independent variables – a condition statisticians call small n large p.
Cross-validation is the easiest way to estimate how accurately a candidate model will predict new data. The simplest approach is to randomly split the data into two parts: a training sample and a validation sample, with 70/30 splits being common. We build the model on the training sample and observe how accurately it predicts on the validation sample. A method known as k-fold validation is generally preferred. This has many variations but one way is to randomly divide the data into five subsamples, build a model on four of these subsamples combined and validate it on the fifth – the subsample that had been held out. This procedure is then repeated four times so that model performance is assessed in each subsample. This entire process conducted five to 10 times with different random subsamples and the results are averaged. The jackknife and bootstrap are two alternatives to cross-validation and k-fold validation.
One general guideline is to keep the model as simple as possible (but not too simple). Simpler models are less prone to overfitting than complex ones, which is related to the bias-variance trade-off. When the type of predictive model and its parameters have been decided the model is re-run on the entire sample. This will be the final model that is actually deployed. Sometimes many models or versions are stacked and the results averaged, though this usually is a backup option due to cost or difficulty of deployment.
Implementation is the graveyard of many good ideas and after model deployment actual sales must be tracked. Marketing is more than identifying target consumers, and ad or promotional campaigns can miss the mark or even backfire. Longer-term effects, in addition, should be assessed since it is possible, for example, that we are making customers more price sensitive and eroding our brand equity. Lastly, the predictive accuracy of any model will deteriorate over time and, accordingly, it should be periodically updated on new data. Even successful implementations must be refined, modified or discarded with the passage of time.
A need for experienced analysts
Understanding people is more critical as we are faced with bigger and messier data. I predict demand will rise for data scientists able to see beyond math and programming who truly understand marketing and consumers. More analytic options also mean more risk and further need for well-trained and experienced analysts. Paradoxically, technology has made it easier to be an incompetent data scientist – in part because of abuser-friendly software – and harder to be a good one because there are now many more ways to answer old questions plus new questions we must now answer.
Understanding the why behind data is critical since marketing isn’t only about predicting behavior, it’s also about changing it. Reverse-engineering from behavior and demographics alone isn’t always easy because two people can:
- do the same things for the same reasons;
- do the same things for different reasons;
- do different things for the same reasons; and
- do different things for different reasons.
There is also the “multiple me” and on different occasions I can do:
- the same things for the same reasons;
- the same things for different reasons;
- different things for the same reasons; and
- different things for different reasons.
We should also admit that some of our behavior is random. People are hard to predict and, like me, you’ve probably given what you thought was the perfect gift to a loved one only to watch it land with a thud!
Statistical methods and machine learners
The death of traditional statistical methods has been greatly exaggerated and, in contrast to some rumors you may have heard, they are actually widely used in predictive analytics. A few examples are descriptive statistics, principal components analysis, PLS regression, multiple regression, logistic regression, survival analysis and mixture modeling. Machine learners, some of which have been developed by statisticians and others by computer scientists and mathematicians, are even more popular. Naive Bayes, k-nearest neighbors, Apriori, artificial neural networks, support vector machines, stochastic gradient boosting and the previously-mentioned random forests rank among the favorites.
A useful model must predict new cases accurately and (ideally) be informative. For example, it will help us understand why some consumers act in some ways and others in other ways. Compared to statistical models, machine learners are often slightly better at prediction but results are usually hard to interpret because they do not use equations that can be readily understood or put into words. This can make them difficult to explain to end users, who are often suspicious of black boxes. Occasionally we can use a machine learner and a statistical model in tandem to accomplish both ends since, if each is adequate, predictions will be highly correlated.
Will it pay off?
Data collection, storage and processing may involve substantial direct costs. All the necessary skills may not be available in-house and, as a rule, many people must be involved in the predictive analytics process. Total time costs can be substantial. Any client will ask, “How do I know predictive analytics will be profitable?” Some degree of skepticism is certainly reasonable – after all, it is nowhere near as established as finance or accounting. Predictive analytics is not guaranteed to pay back and managing client expectations is critical – there may only be a small, rusty needle in that big expensive haystack! Being upfront is the best policy, though technical language should be used minimally if at all.
For quite a while now managers have complained of information overload and many are already overstretched. There are other obstacles predictive analytics faces as well. Every effort must be made to prevent data breaches from occurring. It’s also easy to forget that customers can become irritated if they are barraged with targeted promotions and ads. Predictive analytics can also be seen as a threat, not an opportunity. C-Level buy-in is critical and it is vital that end users be active team participants.
However mesmerizing predictive analytics may be it is important to understand that it’s not magic and cannot save a company from poor management. Predictive analytics is also not a substitute for marketing research and synergizes very well with traditional marketing research. Utilizing various sources of information provides richer insights into what consumers do and why. This makes marketing easier and more effective.
Learning resources
Predictive analytics is not for everyone but if you are interested in learning more about it there are now a number of resources available in addition to massive open online courses and degree programs that did not exist at all until recently. Two popular Web sites are KDnuggets and Data Science Central, though the discussions can be quite detailed and technical. Data Mining Techniques (Linoff and Berry) is a big volume but a non-technical and very readable introduction to data mining and predictive analytics. Some other books I’ve found helpful are Data Architecture: A Primer for the Data Scientist (Inmon and Linstedt), Applied Predictive Modeling (Kuhn and Johnson) and An Introduction to Statistical Learning (James et al.). I’ve listed a number of books and resources here.
Please bear in mind that marketing researchers, marketers, statisticians and computer scientists often use different jargon or the same jargon differently. Don’t assume everyone knows what you are talking about – take the time to clearly communicate!
Kevin Gray is president of Cannon Gray, a marketing science and analytics consultancy. A version of this article first appeared in Quirk’s as Data, data, data: Understanding the role of predictive analytics on September 28, 2015.
Article by channel:
Everything you need to know about Digital Transformation
The best articles, news and events direct to your inbox
Read more articles tagged: Featured, Predictive Analytics
Popular Now
Related Articles
