As the avalanche of data continues, so does its evolution. Big data is evolving, but it needs help as there are so many complexities in Data. The secret recipe here for a successful predictive analytics project starts with housekeeping or cleansing, basically filtering out all of the dirt, noise, invalid data and misleading data. Once this has been done the data has evolved into now what we can call Smart Data. From Smart data we can now start to extract the value of predictive analytics.
So how do we get from Big Data to Smart Data to Tangible value? this is the first question and the second is how fast must data capture take place? considering the speed at which it’s being generated. Can visualisation of the Raw Data assist as to what to correct, exclude or even include? So many questions.
Searching for the value in the Data
Mr Ravi Karupiah, a good friend of mine has just climbed Mount Kilimanjaro in Tanzania, the preparation for this expedition has been months in the planning, any successful journey takes serious preparation.

Planning & Preparation leads to success
Predictive Analytics in essence is a deep dive into huge amounts of Data. If the data is not well prepared, the predictive analytics model will emerge from the dive without any fish (results) in the net. The key to finding VALUE in Predictive Analytics is to prepare the data both THOROUGHLY and METICULOUSLY, so that your model will yield the best possible predictions.
First things first
Processing Data beforehand can be a stumbling block in the predictive analytics process, but it must be done! If you are not sure about Predictive Analytics just quite yet you can access a whole series on PA which I started in 2015, the first post can be followed on this link
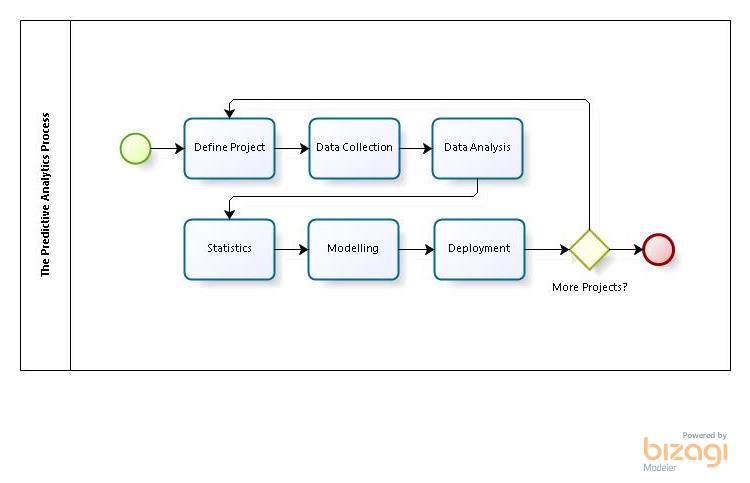
Gaining experience in building predictive models and in particular preparing data teaches you the importance of patience. Selecting and processing. cleansing and preparing (Data Collection) is a time consuming and laborious task. It is by far the most time consuming task in the whole of the Predictive Analytics process (Above). However, proper and systematic preparation of the data will significantly increase your chances of your data analysis bearing fruit.
Fruit and Big Data
Big Data is very much like a large pomelo, using the fruit analogy. You not only have to remove the Yellowish Green peel, but the thick white pith and and skin to get to the nucleus, the nucleus being the bast part inside the fruit.
Data Validity
The first time that you encounter data you can almost guarantee that much of it will not be valid, why? Most data will be incomplete (missing attributes or values) or noisy (containing outliners or errors). A recent experience of a friend of mine happened in the biomedical bioinformatics field, where outliners that were present lead the analysis to generate incorrect and misleading results. The outliners were in Cancer sample results which skewed the accuracy of potential medical treatments. Gene expression samples appeared as false cancer positives because they were analysed against a sample that contained errors.
Inconsistent data that contains discrepancies in data attributes. For example a data record may have two attributes that don’t match. Post code 60000 should correspond to Kuala Lumpur State, not for example Penang.
Invalid data can lead to incorrect predictive modelling, which leads to misleading analytical results, that will cause bad executive decisions. What would you think about a marketing department sending out diaper coupons to people that had no children, fairly obvious mistake. However, it has happened when the manufacturer of diapers got invalid results from their predictive analytics model.
The Challenge of Data Variety
Another challenge in big data is the absence of uniformity. This is known as Data Variety. The absence of this uniformity comes from the endless stream of unstructured text data (generated from emails, presentations, project reports, texts, tweets, etc etc) to Structured Data such as Bank Statements, geolocation data and customer demographics. Collection and aggregation of this data is a complex task.
How do you integrate data generated from different systems such as Twitter, Google and various third parties that track a multitude of customer data?
The answer to this question, is that there is no common solution to this problem! Every situation is different and data scientists end up doing all sorts of maneuvering and gyrations to integrate the data and prepare it for analytics.
Again it must be said that this is the most time consuming task within the whole predictive analytics process.
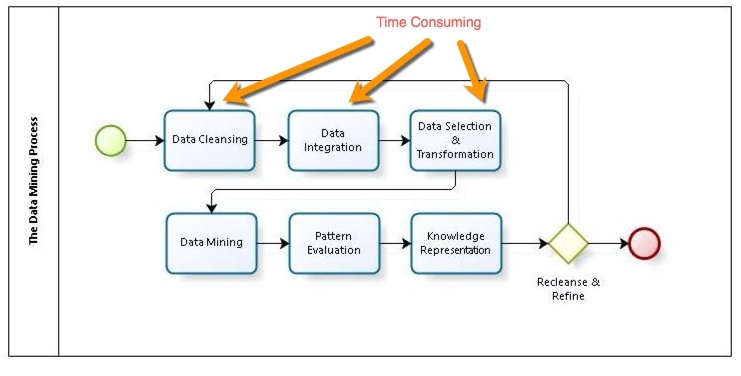 So to integrate all of these type of data we have to find a solution. A simple solution to this problem would be to agree with you data providers a standard data format that your system can accommodate. This framework should make it possible for the data to be both Machine readable as well as Human readable, you might even call it a new language that all Big Data sources will speak once they get into your Big Data World.
So to integrate all of these type of data we have to find a solution. A simple solution to this problem would be to agree with you data providers a standard data format that your system can accommodate. This framework should make it possible for the data to be both Machine readable as well as Human readable, you might even call it a new language that all Big Data sources will speak once they get into your Big Data World.
Another, but not Final Challenge
There is one other challenge to be considered here and that is the Velocity at which the data is moving or streaming. At what rates is the data generated, captured or delivered. How do we keep up with it? With the data growing all the time capturing smart data from Big Data becomes even more challenging. Yet again there is no simple solution to this challenge, but you must ask:-
- How often do you want to capture data?
- What can we afford in both resources and finances?
If for example you were lucky enough to own your own supercomputer and had enough funds available, then capture as much data as you possibly can. The final thing to take into consideration here is, how of that data is changing!
A final thought
There is a common mistake amongst people when they talk about Big Data is that they define it as large amounts of data. Big Data is not just about BIG because of volume, it is about all three dimensions Volume, Variety and Velocity and the challenges faced within them.
Article by channel:
Everything you need to know about Digital Transformation
The best articles, news and events direct to your inbox
Popular Now
Related Articles

